This project is my attempt at creating a tool that creates the auto-generated playlists of my dreams, with an added bonus of being a playlist maintainer. Once set up, a user can just add songs to their liked songs and my playlist manager will auto-sort those songs into the correct playlist. I am still implementing the project, so this post is simply both a technical and non-technical high-level overview of the project. Posts on the fine grained details will follow. The source code for this project is available here!
Table of Contents
Open Table of Contents
What Even Is This, AKA Overview
Problem being addressed
I listen to an odd variety of music. The music I listen to on my own when running or working is very different than the music I play in the car with friends or family. I am not a fan of Spotify’s recommendation methods, where it gives me daily mixes or radios that only partially have songs from my library. I especially wish I could have auto-generated playlists that only include the songs from my library of liked songs, rather than spotify’s recommended mixes which include both songs from my library and suggested songs.
To be specific about the problem I am trying to address and how my tool will fix it, consider the following situation I frequently find myself in.
My music taste is fairly bimodal, where I really like singing along to songs that fall into or near the indie rock genre, and I also really like blasting hyperpop and breakcore while I work or go on runs. For anyone unfamiliar with these genres, they are characterized by dissonant and incredibly loud sections.
Because my music taste isn’t unimodal, I can’t just have one big playlist and put it on shuffle. If I’m in the car with friends, I’m skipping all the breakcore and hyperpop. If I’m trying to hunker down and burn through work, I’m skipping all the indie rock songs. I also always inevitably get tired of maintaining multiple playlists, and am now left with a huge graveyard of unused playlists.
How to solve the problem
A simple solution to this would be to create playlists split by genre, where we create one playlist for each genre (or user defined genre grouping) found in the liked songs. This approach, however, was not granular enough for me and I would disagree with some of the classifications.
I realized that coming up with a fixed set of rules to classify these songs was not going to work, and that classifying music based on “vibes” required a much more adaptable classification system which used variables I could not even consider. I looked to neural networks to address this issue instead.
A neural network is a predictive algorithm which is first trained with training data items where we provide both our input data, and what the output prediction should be for that input. The algorithm is trained using this data to refine what weights it assigns to each factor we provide in the data associated with each item. In our case, we are specifically looking to assign a track to one of finite playlists, and our output will be a label corresponding to one of the possible playlists. For example, our trained algorithm might assign a large negative weight to really high beats per minute when deciding if a song should be classified as a good group song, resulting in songs with a high beats per minute being put in the solo category.
A drawback of this method is we would need user input to generate the labels for the training data, removing our dreams of creating a fully automated playlist manager. The huge benefit in return here is the algorithm would be adaptable to the dataset we apply it to, and thus can be personalized for each user’s listening tastes. I decided this tradeoff was worth it and set to implementing a program that trained and returned a neural network to classify these songs into user specified playlists with minimal user input.
Tech Stack
tl;dr
- Rust for literally everything
- Burn for constructing the neural network
- Tokio for asynchronous runtime
- SQLite for database management
- Rayon for multi-threading
What is Rust and why?
I chose to implement this project using pure Rust, a low-level programming language that most relevantly offers incredible speed advantages when compared to traditional data science languages like Python. Training a neural network is a computationally intensive process, and I figured the more efficient I can make that, the better shot I have on making an app with widespread applicability instead of just something only I would use. My hope is the resulting app will be quick enough to genuinely offer an improvement for people rather than the app just being the result of my long-winded coding exercise.
To be entirely honest though, I kind of wanted to conduct a long-winded coding exercise. My background in applied statistics was limited to academic projects - even outside of the classroom. I am determined to transfer these experiences from a purely academic context to a more generally practical purpose. I taught myself the Rust programming language by reading through the incredible Rust Book and engaging in smaller projects using the language. I am yet however to implement a large project that requires planning and library development, and I aim to use this project to develop and showcase those skills.
Why these tools within Rust?
Burn
Burn is the foundation of this project. All the other packages here exist to support our implementation of the Burn library. Burn is a nascent machine learning library made in Rust; it provides almost all of the underlying tooling necessary for us to build a neural network. For people familiar with the python package PyTorch, burn is basically rust’s version of PyTorch. It is unique in this sense because a majority of the other machine learning libraries I could find for Rust were instead wrappers for PyTorch. By implementing the library in Rust instead of wrapping the existing Python library, we can expect an incredibly significant decrease in our training and inference times for our neural network.
Tokio
Tokio is an asynchronous runtime in Rust. Using it allows me to make multiple (kind of) simultaneous calls to Spotify when I use their API (details in [[Spotify Playlist Manager Overview#Implementation|implementation]]). This drastically speeds up the generation of input-data, allowing the user to spend minimal time waiting for the app between user inputs.
SQLite
SQLite is a lightweight SQL database engine. The size and complexity of our data is relatively small, so SQLite serves our purposes without being unnecessarily complicated. Additionally, the Burn package includes some built in methods to interact with SQLite databases, allowing us to easily integrate SQLite as a database management tool.
Rayon
Rayon is a rust library that allows us to easily implement thread pools and convert our single-threaded application into a multi-threaded one. We expect somewhat significant decreases in our runtime by doing this, for the simple reason that using more resources will allow us to execute faster (the computational overhead accumulated by multi-threading is negligible in comparison to benefits). However, we do not expect major improvements despite our program being computationally heavy as we will implement the most computationally heavy task, the training, with the user’s GPU rather than their CPU.
Non-technical Overview
tl;dr
- We consider mutuality and completeness, allowing for both to either be true or false. This results in four cases we need to consider.
There are a couple of ways I imagine a user interacting with this app. We will explore these in this section in an abstracted and non-technical context.
The expected use case for our app would be a user setting their liked songs on spotify as their source of songs to put in playlists, and wanting to construct playlists based on the contexts in which they listen to particular track (Ex: songs for listening alone vs songs for listening in a group). However, we can abstract this use case so that any playlist can be chosen as the source for songs, allowing our app to expand its functionality with minimal overhead. In a generalized view, the goal of this project is to take a set of songs which we will call the motherlist, and construct several subsets of songs which we call sublists - these sublists are just the resulting playlists we want.
In constructing these sublists, we have two independent considerations that need addressing.
- Mutuality: Does the user want every song in the motherlist to be placed in one and only one sublist? If so, we can create a neural network that simply finds the most likely sublist to assign each track and stop there. This is the mutual case. If the user doesn’t mind some songs being in multiple sublists, we need to construct a neural network that can classify our songs based on some other threshold. How do we discern if a song should also be included in the second most likely sublist it would be assigned to? This is the non-mutual case.
- In the language of set theory, where S is the set of our sublists, the mutual case is represented by
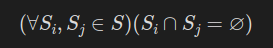
- Completeness: Does the user want every song in their motherlist to be assigned to a sublist. Consider a user who very leniently adds to their liked songs (aka me), but wants their playlists to be a bit more selective (again, me). This user would not necessarily want every song in their motherlist to end up in a sublist, and as such we need to “trash” some of the songs and find a may to set some type of threshold for songs that will not make it into any of the sublists. This is what we will call the incomplete case. Instead, a user could love every song in their motherlist and want to ensure every song will be in a sublist. This is the complete case.
- In the language of set theory, where S is the set of our sublists and M is our motherlist, the complete case is represented by
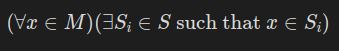
Our neural network will implement any combination of these 2 factors, resulting in a total of four cases we need to address. We will begin by addressing the case with the lowest complexity and move to implementing higher complexity cases afterwards. There is also the much more complicated consideration of composing layers, where each layer contains a different set of sublists and can address a different case from other layers. I address how our final implementation considers this later in this post.
Mutual and Complete
The simplest and most intuitive way of turning our saved tracks into groups of playlists is by creating a bunch of playlists where every song in our saved tracks appears in exactly one of those playlists. In the language of set theory, we are partitioning the set of saved tracks.
Partitioning our saved tracks means to map every element within the set of saved tracks to a non-empty subset. Each element is included in only one of these subsets. All sublists are disjoint and their union is the motherlist.
Consider the following example of a mutual and complete classification where we once again want a solo and group sublist (side note, every song listed here is an absolute banger and comes highly recommended).
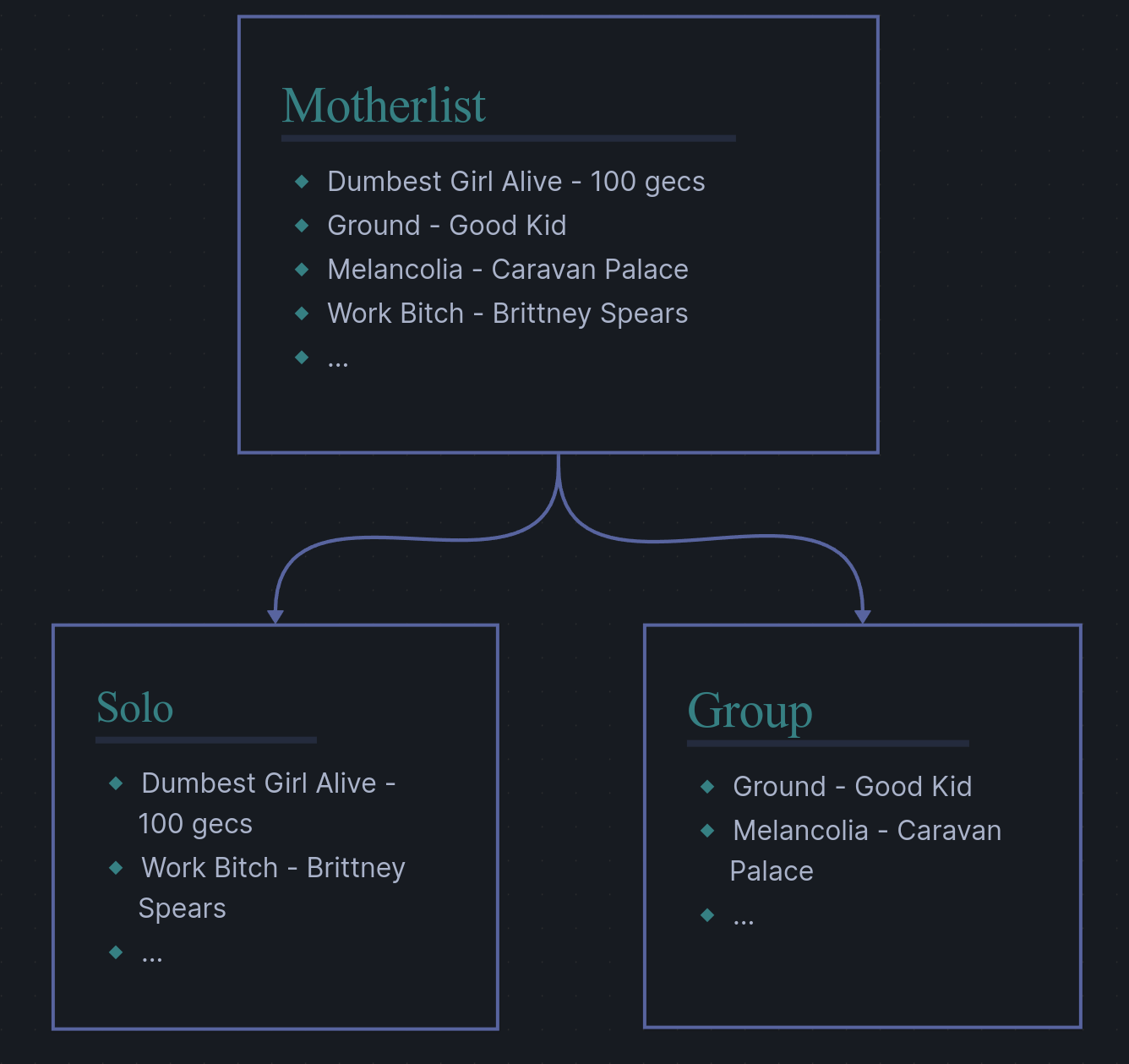
As you can see, this case is somewhat like placing items into boxes when moving. Every item has to go into a box, and no item can be in two boxes at the same time. We can now more easily explore the other three cases by defining them in relation to this case.
Mutual and Incomplete
Compared to the mutual and complete case, the mutual and incomplete case is similar, but almost as if its done more clumsily; we drop some songs along the way and don’t stop to pick them up. Using the same solo and group sublists, we can see how this might look like.
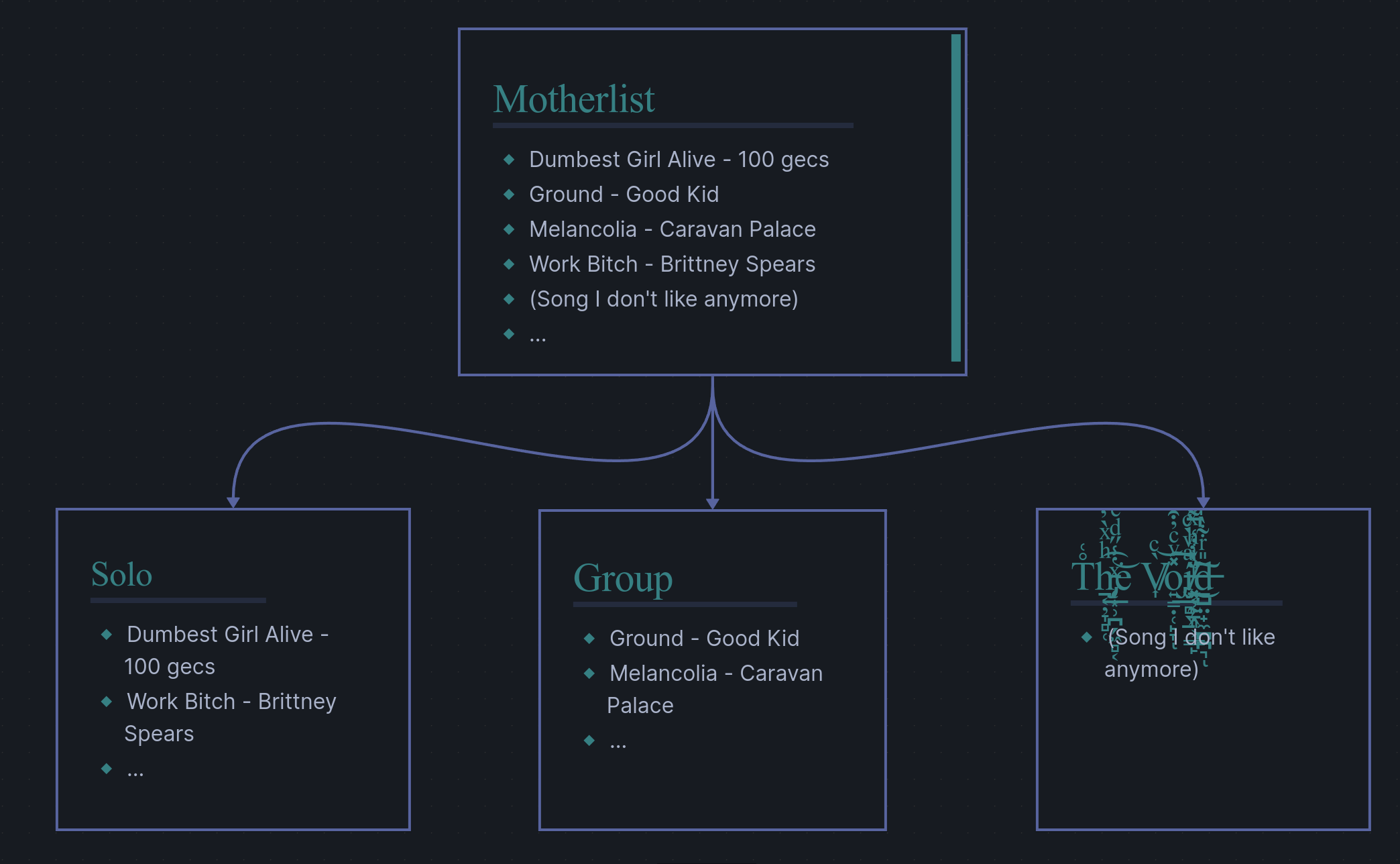
I mostly included the “the void” section for a visual aid, but the above diagram is entirely accurate to how our actual implementation will work. We are simply going to consider the void as another sublist, just one we won’t eventually tell spotify we want to make a playlist from in our account. This allows us to effectively create a trashlist where we dump all the songs we don’t want to be placed into playlists. As an analogy for this case, consider moving once again but using the KonMari method of organizing. This is the method popularized by Mari Kondo where (simplified explanation here) you keep only the things that spark joy for you. Thus, we throw away some things while moving, putting them into the bin rather than into any one box.
Non-mutual and Complete
Here, we lose the moving analogy and allow ourselves to place songs into multiple sublists. We also lose the void for this case since we are considering a complete case. Now, we allow for songs to end up in multiple sublists, and all songs must be in a sublist. Again, refer to the image below for a corresponding visual.
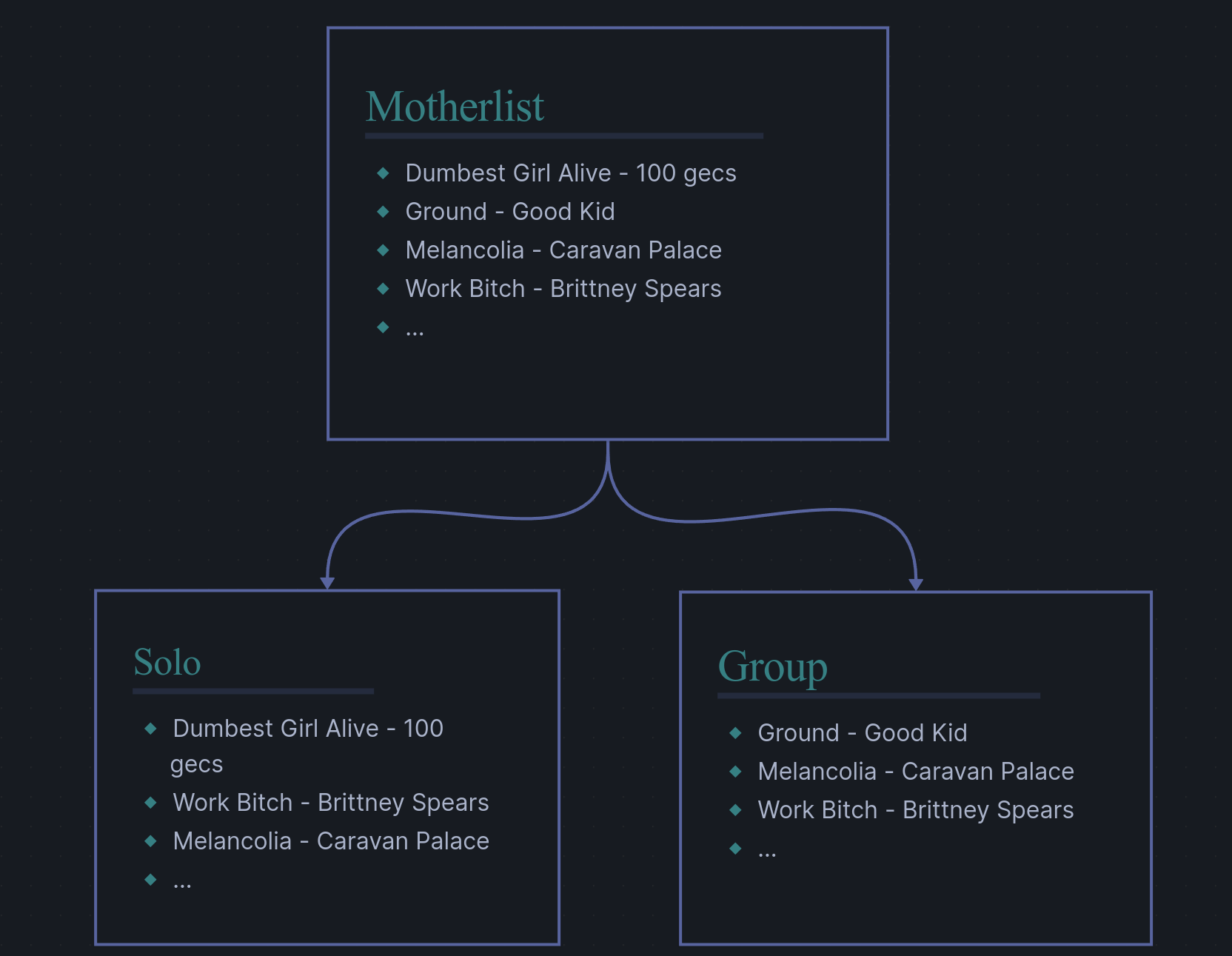
An analogy that’s so appropriate that I don’t know if it’s an analogy anymore is as follows. Consider your favorite songs, each of them is attributed to at least one genre, and some of them are attributed to multiple genres - these we call fusion songs. Much like sorting by genre, each song has one sublist, and some of them are attributed to multiple sublists - I haven’t come up with a cool name like fusion for these.
Non-mutual and incomplete
Lastly, we consider the most chaotic case. Here, we have no restrictions on the sublists besides they must be subsets of the motherlist. This is in honesty the base case, it is just the hardest to explain hence why it is the last one listed. Now, we bring back the void as an option, allowing users to discard songs, and we also allow users to assign songs to multiple sublists. Below is an image of what this might look like
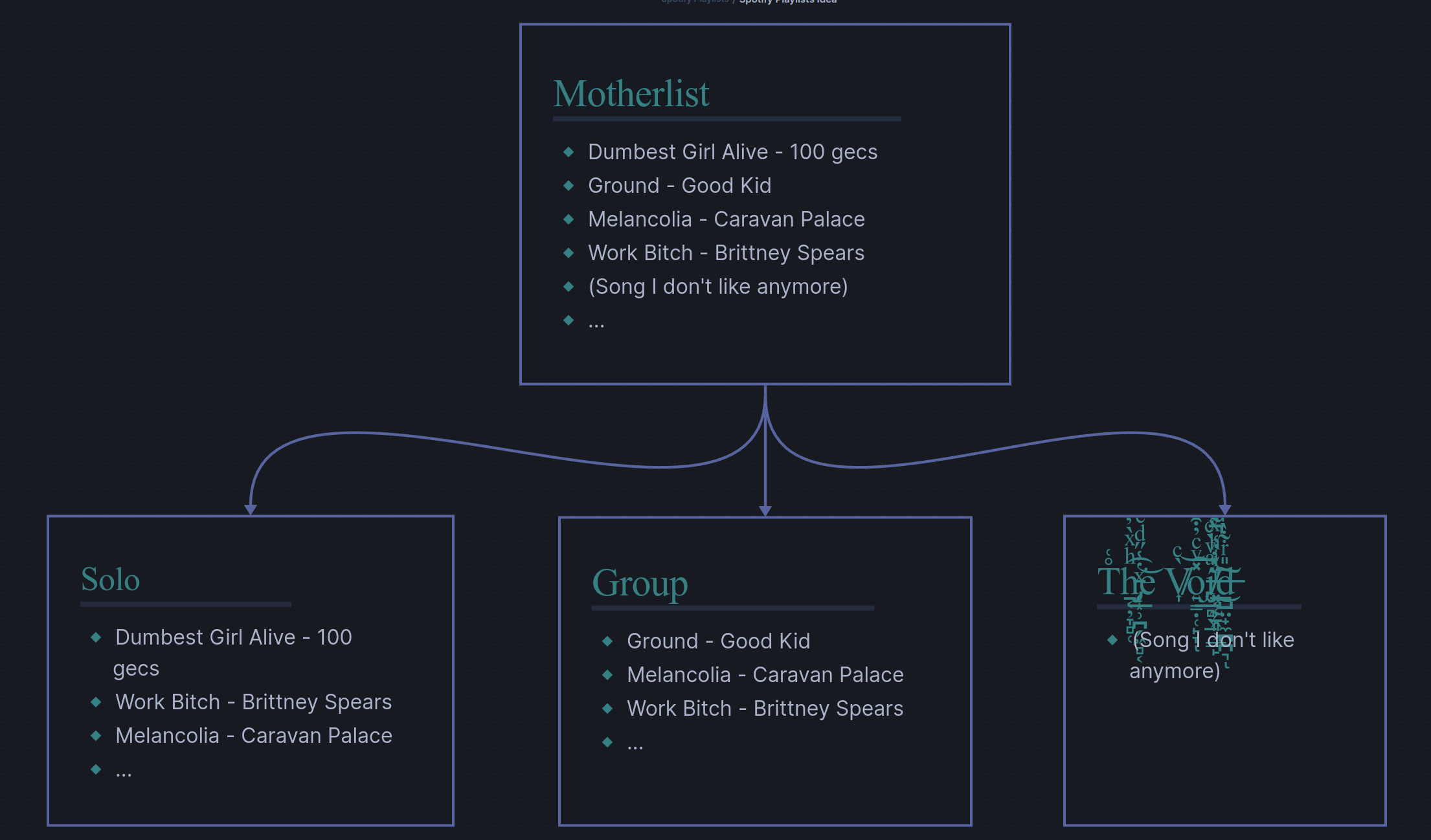
This case is also incredibly likely to be a desired feature, but it is the hardest to implement. It will be the last feature made only after the project is stable and otherwise complete.
For an analogy to describe this case, consider tags on some social media platform. You don’t have to tag your post with anything, and if you do, you can tag it with (presumably) as many tags as you would like. Similarly, we do not have to put a song in a sublist, and if we do, we can place them into as many sublists as we like